
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
线性表(Linear List)就是数据排成像一条线一样的结构。每个线性表上的数据最多只有两个方向。除了数组,链表、队列、栈也是线性表结构。
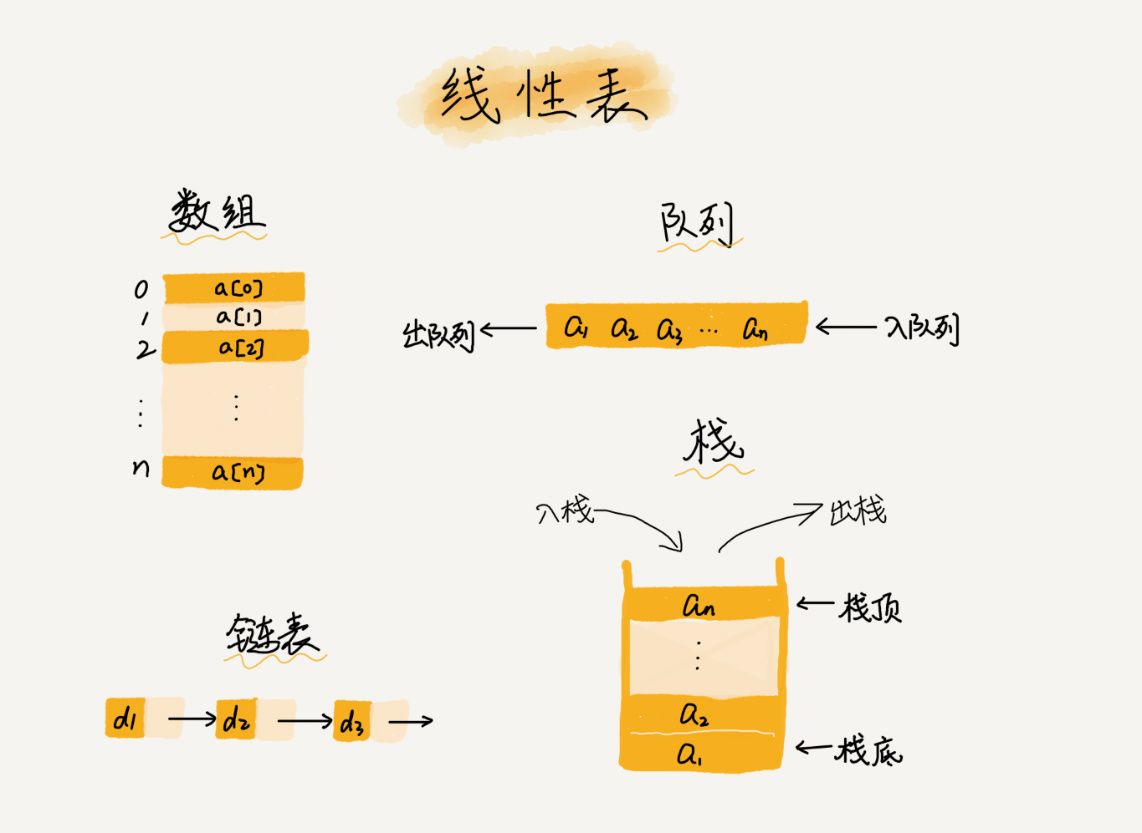
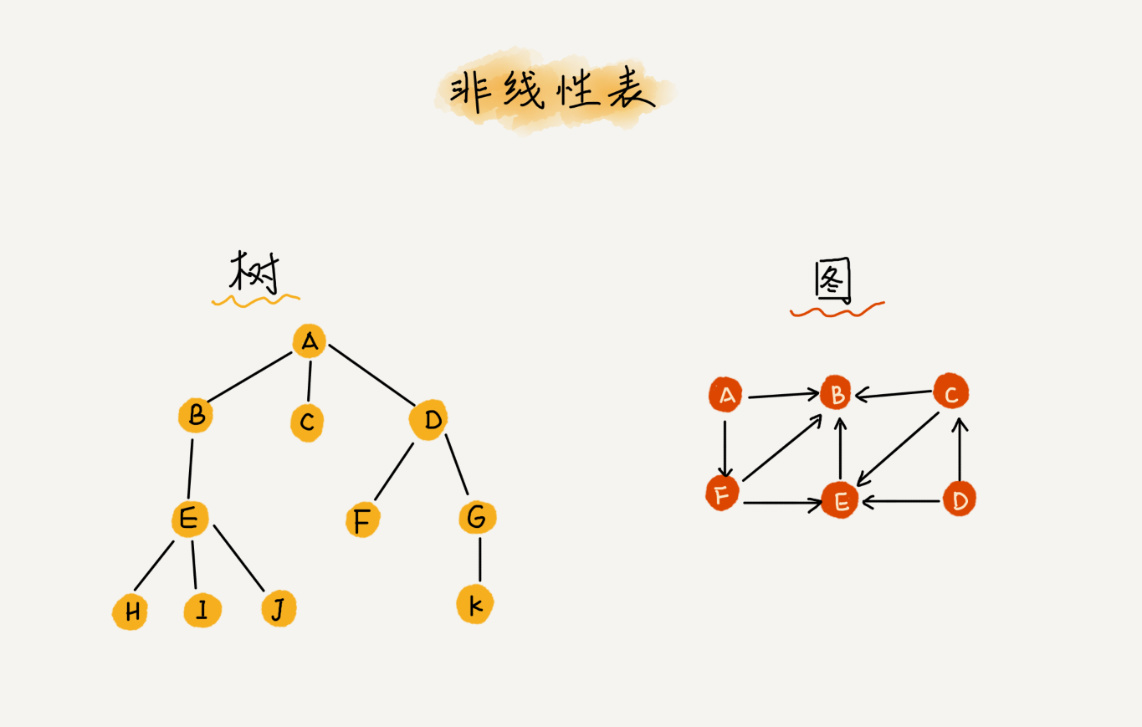
与线性表对立的是非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
连续的内存空间和相同的数据类型:
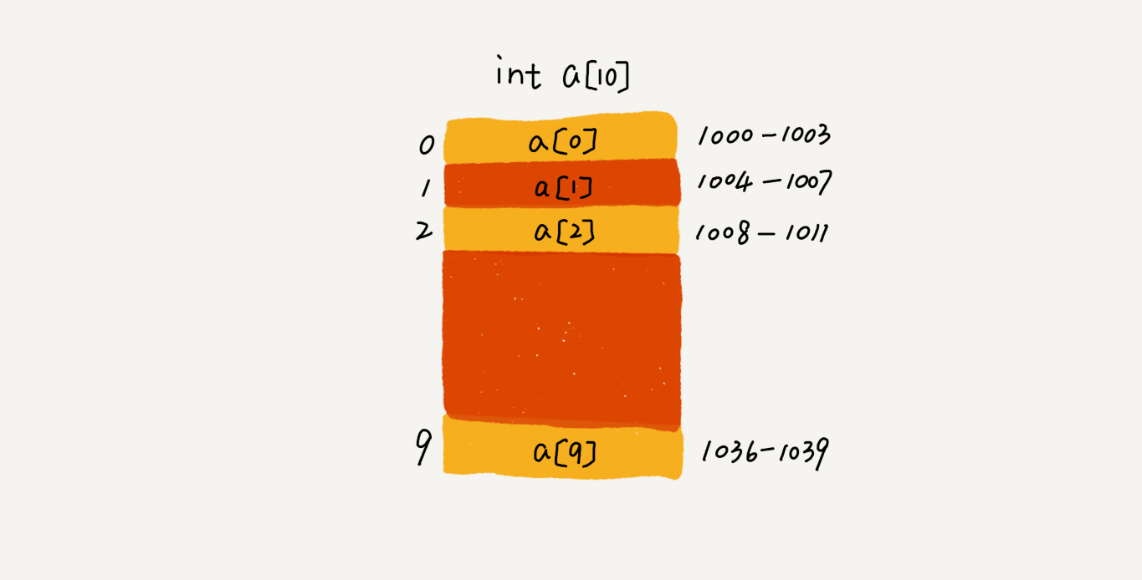
数据根据下标随机访问的时间复杂度为 O(1)
数据的插入和删除很低效:
如果删除数组末尾的数据,最好情况时间复杂度为 O(1)
如果删除开头的数据,则最坏情况时间复杂度为 O(n)
平均情况时间复杂度也为 O(n)。
如果数组是排好序的,时间复杂度如上;如果不是排好序的,可以用下面的办法:
假设数组 a[10] 中存储了如下 5 个元素:a,b,c,d,e。
我们现在需要将元素 x 插入到第 3 个位置。我们只需要将 c 放入到 a[5],将 a[2] 赋值为 x 即可。最后,数组中的元素如下: a,b,x,d,e,c。

使用这种技巧:在特定的场景下,在第K个位置插入一个元素的时间复杂度就会降为O(1)
什么情况下使用数据?
Java ArrayList 无法存储基本类型,比如int、long,需要封装未Integer、Long类,而Autoboxing、Unboxing则有一定的性能消耗;所以如果特别关注性能,或者希望使用基本类型,就可以选择数据。
如果数据大小事先已知,并且对数据的操作非常简单,用不到ArrayList提供的大部分方法,也可以直接使用数组。
当表示多维数组时,用数组往往会更加直观,比如 Object[][] array;而容器的话需要这样定义:ArrayListarray。
为什么大多数编程语言中,数组要从0开始编号,而不是1开始呢?
从数组的存储模型上来看,“下标”最确切的定义应该是“偏移量(offset)”。
如果用a代表数组的首地址,a[0]就是偏移量为0的位置,也就是首地址,a[k]就表示偏移量k个 type_size 的位置,所以计算 a[k] 的内存地址只需要用这个公式:
a[k]_address = base_address + k * type_size
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k] 的内存地址就会变为:
a[k]_address = base_address + (k-1)*type_size
如果从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对CPU来说就是多了一次减法指令。
动力节点在线课程涵盖零基础入门,高级进阶,在职提升三大主力内容,覆盖Java从入门到就业提升的全体系学习内容。全部Java视频教程免费观看,相关学习资料免费下载!对于火爆技术,每周一定时更新!如果想了解更多相关技术,可以到动力节点在线免费观看数据结构视频教程哦!
 代码小兵872
代码小兵872
30篇文章贡献98658字
提枪策马乘胜追击04-21 20:01
代码小兵87207-15 12:10
杨晶珍05-11 14:54
杨晶珍05-12 17:30


 京公网安备 11030102010736号
京公网安备 11030102010736号