
MyCat:开源分布式数据库中间件, 这里定义的很简单, 就是分布式数据库的中间件.
其实Mycat 是可以进行mysql集群的中间件, 我们可以对mysql来分库分表 来应对日益增长的数据量. 每台机器只存少量数据, 数据总和是分布式的机器上数据量总和.

例如我们一个表中有512条数据(当然实际情况可能有成千上万条数据), 那么现在我们有三台机器装有mysql数据库, 我们想将这些数据按照一定规则的存储在三台机器上, 那么我们设定规则:
表的id%/512 取的结果按照区间分别存储在三个不同的数据库中, 但是这三个数据库又要统一的对外提供服务.
那么这些分割算法 以及 统一对外提供服务是谁来提供支持的呢? 当然就是我们今天要讲的Mycat了.
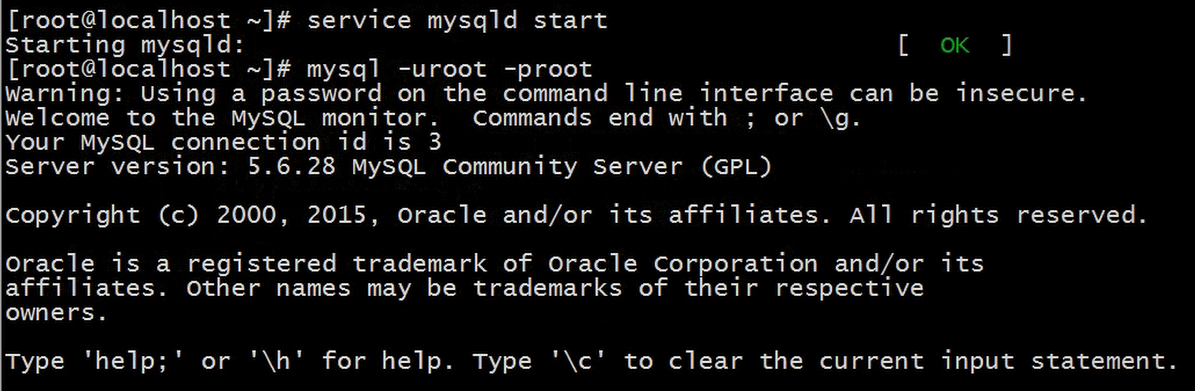
连接Linux中的mysql数据库:(这里我们的Linux IP为192.168.200.140)
查看表结构:
查看1库中的商品ID(这个已经是通过Mycatt分好的)
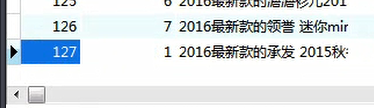
查看1库中的商品ID(这个已经是通过Mycatt分好的)
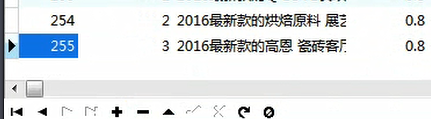
查看1库中的商品ID(这个已经是通过Mycatt分好的)
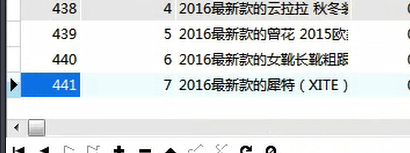
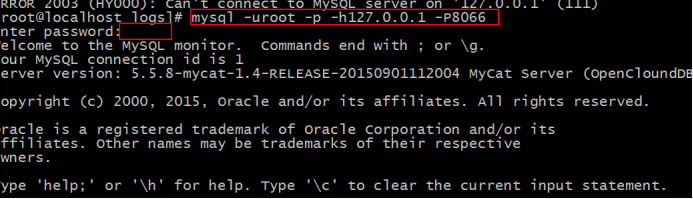
在项目组中设置默认连接为Mycat:(关于这里数据库为什么是babasport而不是babasport1或babasport2等, 后面会说明)

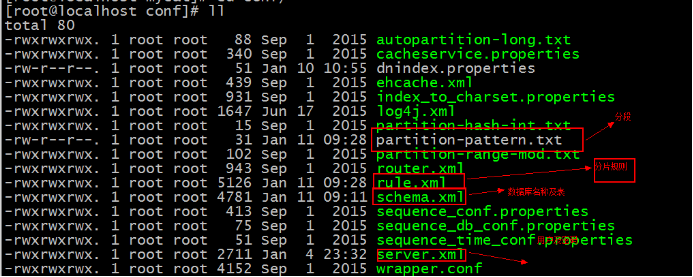
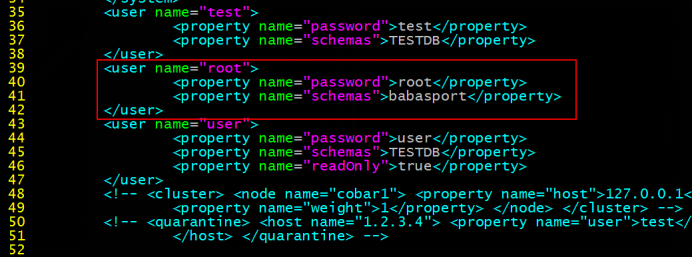
1.用户名及密码设置:server.xml:
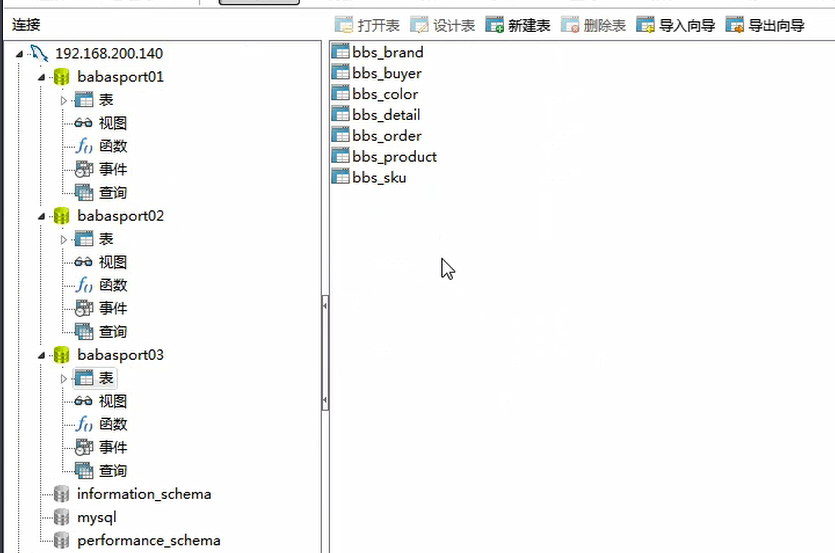
2.逻辑库中的定义表:schema.xml:
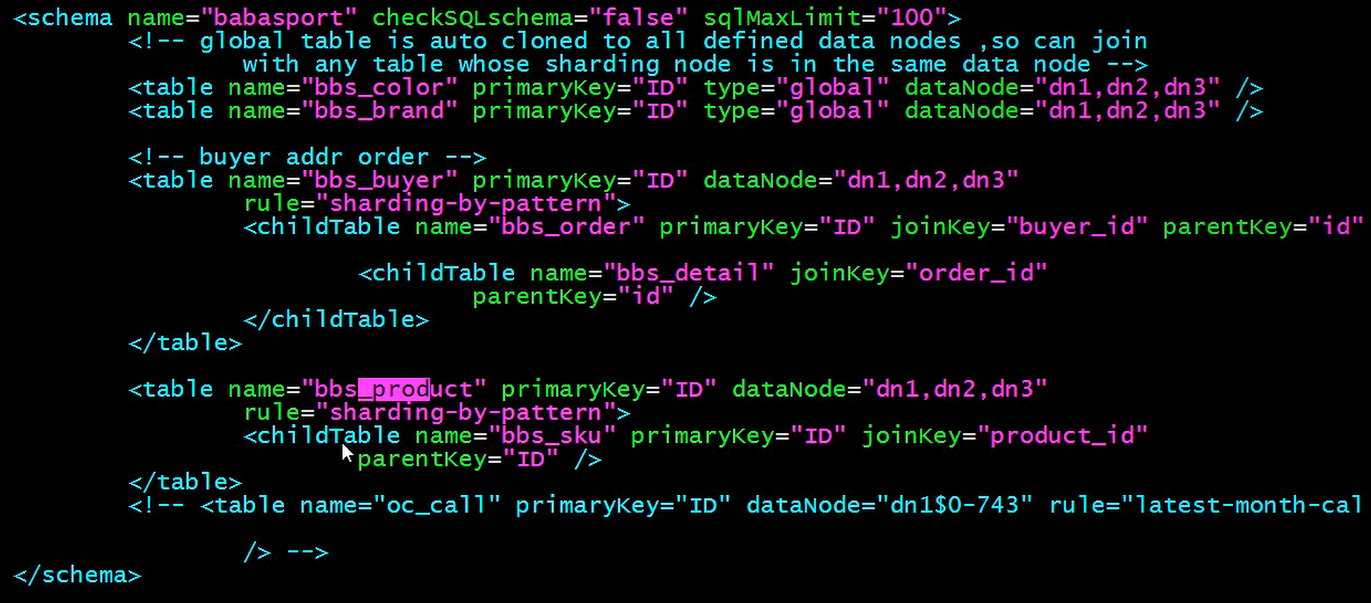
这里需要说一下, 因为bbs_color和bbs_brand表中的数据很少, 所以这里不需要分库分表, 直接设置成全局表就行, 也就是这两个表中的数据在1,2,3 库中都是一样的.
还有就是childTable, 我们拿bbs_product和bbs_sku来说, 因为商品product和库存bbs_sku是一对多的关系, 那么我们就希望商品id为1 的商品所对应的库存都是在同一个库中的, 这样查询的话就不用跨库了.
同样这里还有一个属性是rule="sharding-by-pattern", 那么接下来我们就要看下这里设定的规则了.
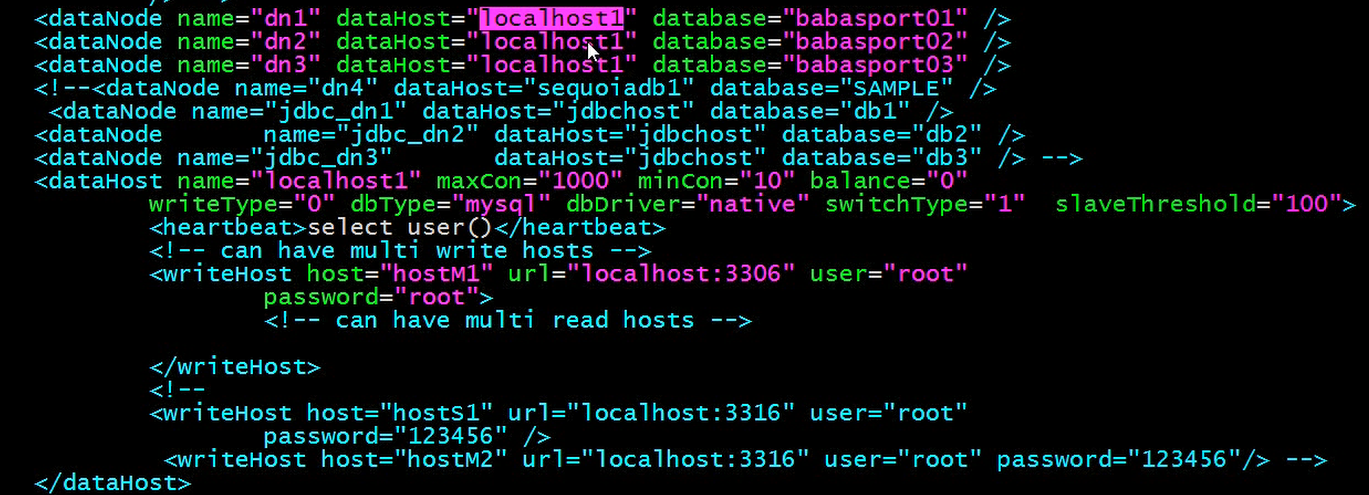
因为上面的schema标签中有定义的那么为babasport, 而且dataNode节点又分别指向dn1, dn2, dn3, 所以这里就可以做到对应了.
我们在项目连接的时候 直接是连接babasport的.
3.查看分片规则: rule.xml
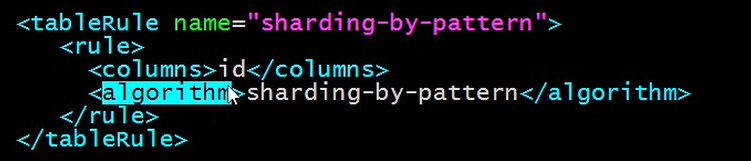
这里指定算法为sharding-by-pattern.
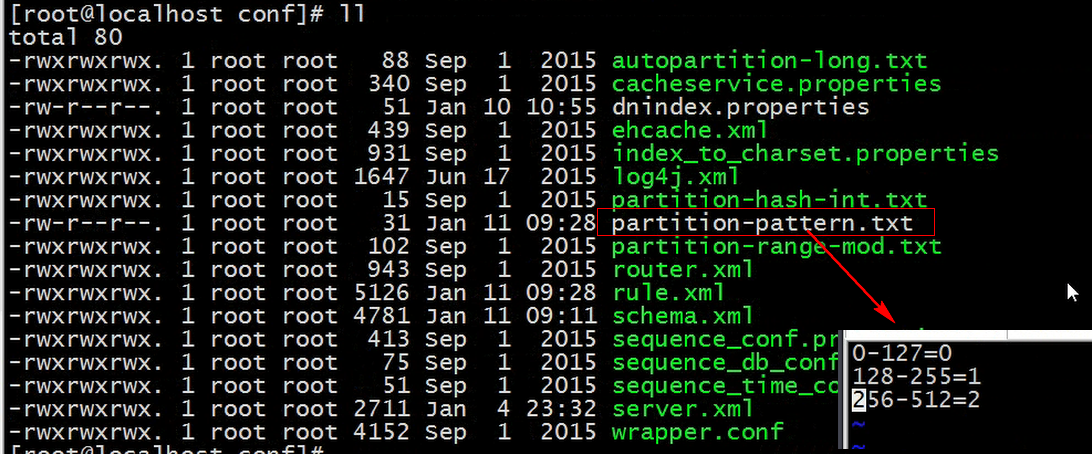
查看算法sharding-by-pattern, 这里指定算法存储在partition-pattern.txt
这里是通过PartitionByPattern这个类来实现的, 这里是对512进行取模, 如果取模过程中出现异常, 那么就放到3库(0,1,2)中进行存储.

查看算法指定文件:
动力节点在线课程涵盖零基础入门,高级进阶,在职提升三大主力内容,覆盖Java从入门到就业提升的全体系学习内容。全部Java视频教程免费观看,相关学习资料免费下载!对于火爆技术,每周一定时更新!如果想了解更多相关技术,可以到动力节点在线免费观看Mycat读写分离视频教程学习哦!
 代码小兵345
代码小兵345
44篇文章贡献168626字
代码小兵69606-03 17:02
代码小兵69606-07 17:03
代码小兵12406-08 16:40


 京公网安备 11030102010736号
京公网安备 11030102010736号



