
在数据切分处理中,特别是水平切分中,中间件最终要的两个处理过程就是数据的切分、数据的聚合。选择合适的切分规则,至关重要,因为它决定了后续数据聚合的难易程度,甚至可以避免跨库的数据聚合处理。 前面讲了数据切分中重要的几条原则,其中有几条是数据冗余,表分组(Table Group),这都是业务上规避跨库join的很好的方式,但不是所有的业务场景都适合这样的规则,因此本章将讲述如何选择合适的切分规则。
如果你的业务中有些数据类似于数据字典,比如配置文件的配置,常用业务的配置或者数据量不大很少变动的表,这些表往往不是特别大,而且大部分的业务场景都会用到,那么这种表适合于Mycat全局表,无须对数据进行切分,只要在所有的分片上保存一份数据即可,Mycat在Join操作中,业务表与全局表进行Join聚合会优先选择相同分片内的全局表join,避免跨库Join,在进行数据插入操作时,mycat将把数据分发到全局表对应的所有分片执行,在进行数据读取时候将会随机获取一个节点读取数据。 目前Mycat没有做全局表的数据一致性检查,后续版本1.4之后可能会提供全局表一致性检查,检查每个分片的数据一致性。 全局表的配置如下
<table name="t_area" primaryKey="id" type="global" dataNode="dn1,dn2" />1
有一类业务,例如订单(order)跟订单明细(order_detail),明细表会依赖于订单,也就是说会存在表的主从关系,这类似业务的切分可以抽象出合适的切分规则,比如根据用户ID切分,其他相关的表都依赖于用户ID,再或者根据订单ID切分,总之部分业务总会可以抽象出父子关系的表。这类表适用于ER分片表,子表的记录与所关联的父表记录存放在同一个数据分片上,避免数据Join跨库操作。 以order与order_detail例子为例,schema.xml中定义如下的分片配置,order,order_detail 根据order_id进行数据切分,保证相同order_id的数据分到同一个分片上,在进行数据插入操作时,Mycat会获取order所在的分片,然后将order_detail也插入到order所在的分片。
<table name="order" dataNode="dn$1-32" rule="mod-long"> <childTable name="order_detail" primaryKey="id" joinKey="order_id" parentKey="order_id" /> </table>1
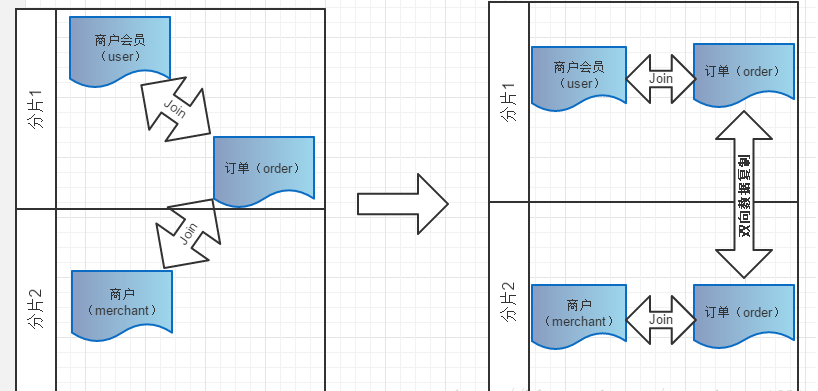
有一类业务场景是 “主表A+关系表+主表B”,举例来说就是商户会员+订单+商户,对应这类业务,如何切分? 从会员的角度,如果需要查询会员购买的订单,那按照会员进行切分即可,但是如果要查询商户当天售出的订单,那又需要按照商户做切分,可是如果既要按照会员又要按照商户切分,几乎是无法实现,这类业务如何选择切分规则非常难。目前还暂时无法很好支持这种模式下的3个表之间的关联。目前总的原则是需要从业务角度来看,关系表更偏向哪个表,即“A的关系”还是“B的关系”,来决定关系表跟从那个方向存储,未来Mycat版本中将考虑将中间表进行双向复制,以实现从A-关系表 以及B-关系表的双向关联查询如下图所示:
键分片 当你没人任何字段可以作为分片字段的时候,主键分片就是唯一选择,其优点是按照主键的查询最快,当采用自动增长的序列号作为主键时,还能比较均匀的将数据分片在不同的节点上。 若有某个合适的业务字段比较合适作为分片字段,则建议采用此业务字段分片,选择分片字段的条件如下:
尽可能的比较均匀分布数据到各个节点上;
该业务字段是最频繁的或者最重要的查询条件。
常见的除了主键之外的其他可能分片字段有“订单创建时间”、“店铺类别”或“所在省”等。当你找到某个合适的业务字段作为分片字段以后,不必纠结于“牺牲了按主键查询记录的性能”,因为在这种情况下,MyCAT提供了“主键到分片”的内存缓存机制,热点数据按照主键查询,丝毫不损失性能。
<table name="t_user" primaryKey="user_id" dataNode="dn$1-32" rule="mod-long"> <childTable name="t_user_detail" primaryKey="id" joinKey="user_id" parentKey="user_id" /> </table>1
对于非主键分片的table,填写属性primaryKey,此时MyCAT会将你根据主键查询的SQL语句的第一次执行结果进行分析,确定该Table 的某个主键在什么分片上,并进行主键到分片ID的缓存。第二次或后续查询mycat会优先从缓存中查询是否有id–>node 即主键到分片的映射,如果有直接查询,通过此种方法提高了非主键分片的查询性能。 本节主要讲了如何去分片,如何选择合适分片的规则,总之尽量规避跨库Join是一条最重要的原则,下一节将介绍Mycat目前已有的分片规则,每种规则都有特定的场景,分析每种规则去选择合适的应用到项目中。
1.分片枚举
通过在配置文件中配置可能的枚举id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则,配置如下:
<tableRule name="sharding-by-intfile"> <rule> <columns>user_id</columns> <algorithm>hash-int</algorithm> </rule> </tableRule> <function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> <property name="type">0</property> <property name="defaultNode">0</property> </function> partition-hash-int.txt 配置: 10000=0 10010=1 DEFAULT_NODE=1123456789101112
上面columns 标识将要分片的表字段,algorithm 分片函数, 其中分片函数配置中,mapFile标识配置文件名称,type默认值为0,0表示Integer,非零表示String, 所有的节点配置都是从0开始,及0代表节点1
defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点 * 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点 * 如果不配置默认节点(defaultNode值小于0表示不配置默认节点),碰到 * 不识别的枚举值就会报错, * like this:can’t find datanode for sharding column:column_name val:ffffffff 1
2.固定分片hash算法
本条规则类似于十进制的求模运算,区别在于是二进制的操作,是取id的二进制低10位,即id二进制&1111111111。 此算法的优点在于如果按照10进制取模运算,在连续插入1-10时候1-10会被分到1-10个分片,增大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。
<tableRule name="rule1"> <rule> <columns>user_id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">2,1</property> <property name="partitionLength">256,512</property> </function>1234567
配置说明: 上面columns 标识将要分片的表字段,algorithm 分片函数, partitionCount 分片个数列表,partitionLength 分片范围列表 分区长度:默认为最大2^n=1024 ,即最大支持1024分区 约束 : count,length两个数组的长度必须是一致的。 1024 = sum((count[i]*length[i])). count和length两个向量的点积恒等于1024 用法例子: 本例的分区策略:希望将数据水平分成3份,前两份各占25%,第三份占50%。(故本例非均匀分区) // |<———————1024———————————>| // |<—-256—>|<—-256—>|<———-512————->| // | partition0 | partition1 | partition2 | // | 共2份,故count[0]=2 | 共1份,故count[1]=1 | int[] count = new int[] { 2, 1 }; int[] length = new int[] { 256, 512 }; PartitionUtil pu = new PartitionUtil(count, length); // 下面代码演示分别以offerId字段或memberId字段根据上述分区策略拆分的分配结果
int DEFAULT_STR_HEAD_LEN = 8; // cobar默认会配置为此值 long offerId = 12345; String memberId = "qiushuo"; // 若根据offerId分配,partNo1将等于0,即按照上述分区策略,offerId为12345时将会被分配到partition0中 int partNo1 = pu.partition(offerId); // 若根据memberId分配,partNo2将等于2,即按照上述分区策略,memberId为qiushuo时将会被分到partition2中 int partNo2 = pu.partition(memberId, 0, DEFAULT_STR_HEAD_LEN);1234567
如果需要平均分配设置:平均分为4分片,partitionCount*partitionLength=1024
<function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">4</property> <property name="partitionLength">256</property> </function>1
3.范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片, start <= range <= end. range start-end ,data node index K=1000,M=10000.
<tableRule name="auto-sharding-long"> <rule> <columns>user_id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule> <function name="rang-long" class="org.opencloudb.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> <property name="defaultNode">0</property> </function>12345
配置说明: 上面columns 标识将要分片的表字段,algorithm 分片函数, rang-long 函数中mapFile代表配置文件路径 defaultNode 超过范围后的默认节点。 所有的节点配置都是从0开始,及0代表节点1,此配置非常简单,即预先制定可能的id范围到某个分片 0-500M=0 500M-1000M=1 1000M-1500M=2 或 0-10000000=0 10000001-20000000=1 4 取模 此规则为对分片字段求摸运算。
<tableRule name="mod-long"> <rule> <columns>user_id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="org.opencloudb.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">3</property> </function>12345
配置说明: 上面columns标识将要分片的表字段,algorithm分片函数, 此种配置非常明确即根据id进行十进制求模预算,相比固定分片hash,此种在批量插入时可能存在批量插入单事务插入多数据分片,增大事务一致性难度。
4.按日期(天)分片
此规则为按天分片
<tableRule name="sharding-by-date"> <rule> <columns>create_time</columns> <algorithm>sharding-by-date</algorithm> </rule> </tableRule> <function name="sharding-by-date" class="org.opencloudb.route.function.PartitionByDate"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2014-01-01</property> <property name="sEndDate">2014-01-02</property> <property name="sPartionDay">10</property> </function>12345678
配置说明: columns :标识将要分片的表字段 algorithm :分片函数 dateFormat :日期格式 sBeginDate :开始日期 sEndDate:结束日期 sPartionDay :分区天数,即默认从开始日期算起,分隔10天一个分区 如果配置了 sEndDate 则代表数据达到了这个日期的分片后后循环从开始分片插入。 Assert.assertEquals(true, 0 == partition.calculate(“2014-01-01”)); Assert.assertEquals(true, 0 == partition.calculate(“2014-01-10”)); Assert.assertEquals(true, 1 == partition.calculate(“2014-01-11”)); Assert.assertEquals(true, 12 == partition.calculate(“2014-05-01”));
5.取模范围约束
此种规则是取模运算与范围约束的结合,主要为了后续数据迁移做准备,即可以自主决定取模后数据的节点分布。
<tableRule name="sharding-by-pattern"> <rule> <columns>user_id</columns> <algorithm>sharding-by-pattern</algorithm> </rule> </tableRule> <function name="sharding-by-pattern" class="org.opencloudb.route.function.PartitionByPattern"> <property name="patternValue">256</property> <property name="defaultNode">2</property> <property name="mapFile">partition-pattern.txt</property> </function> 1234567
partition-pattern.txt
# id partition range start-end ,data node index ###### first host configuration 1-32=0 33-64=1 65-96=2 97-128=3 ######## second host configuration 129-160=4 161-192=5 193-224=6 225-256=7 0-0=7123456789101112
配置说明:上面columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,defaoultNode 默认节点,如果配置了默认,则不会按照求模运算 mapFile 配置文件路径 : 配置文件中,1-32 即代表id%256后分布的范围,如果在1-32则在分区1,其他类推,如果id非数据,则会分配在defaoultNode 默认节点
String idVal = “0”; Assert.assertEquals(true, 7 == autoPartition.calculate(idVal)); idVal = “45a”; Assert.assertEquals(true, 2 == autoPartition.calculate(idVal));123
动力节点在线课程涵盖零基础入门,高级进阶,在职提升三大主力内容,覆盖Java从入门到就业提升的全体系学习内容。全部Java视频教程免费观看,相关学习资料免费下载!对于火爆技术,每周一定时更新!如果想了解更多相关技术,可以到动力节点在线免费观看Mycat读写分离视频教程学习哦!
 代码小兵279
代码小兵279
75篇文章贡献270037字
代码小兵69606-03 17:02
代码小兵69606-07 17:03
代码小兵12406-08 16:40


 京公网安备 11030102010736号
京公网安备 11030102010736号



